Mở đầu
Trong nhiều năm, công nghệ nhận diện ký tự quang học (OCR) truyền thống dựa trên phương pháp khớp pixel thường là một điểm nghẽn lớn trong quy trình số hóa của doanh nghiệp. Các lỗi phổ biến như lệch định dạng bảng biểu, sai lệch phông chữ và tỷ lệ lỗi cao buộc con người phải thực hiện rà soát thủ công, làm giảm hiệu suất của các chuỗi cung ứng dữ liệu.
Bước sang năm 2026, ranh giới công nghệ đã dịch chuyển rõ rệt. Phương pháp khớp pixel tĩnh đã nhường chỗ cho kỷ nguyên Trí tuệ Tài liệu (Document Intelligence). Yêu cầu hiện tại của các hệ thống doanh nghiệp không chỉ dừng lại ở việc đọc chữ, mà là hiểu sâu sắc cấu trúc, ngữ cảnh kỹ thuật và ý nghĩa nghiệp vụ của từng loại tài liệu, từ các bản vẽ kỹ thuật phức tạp đến các văn bản pháp lý đa ngôn ngữ.
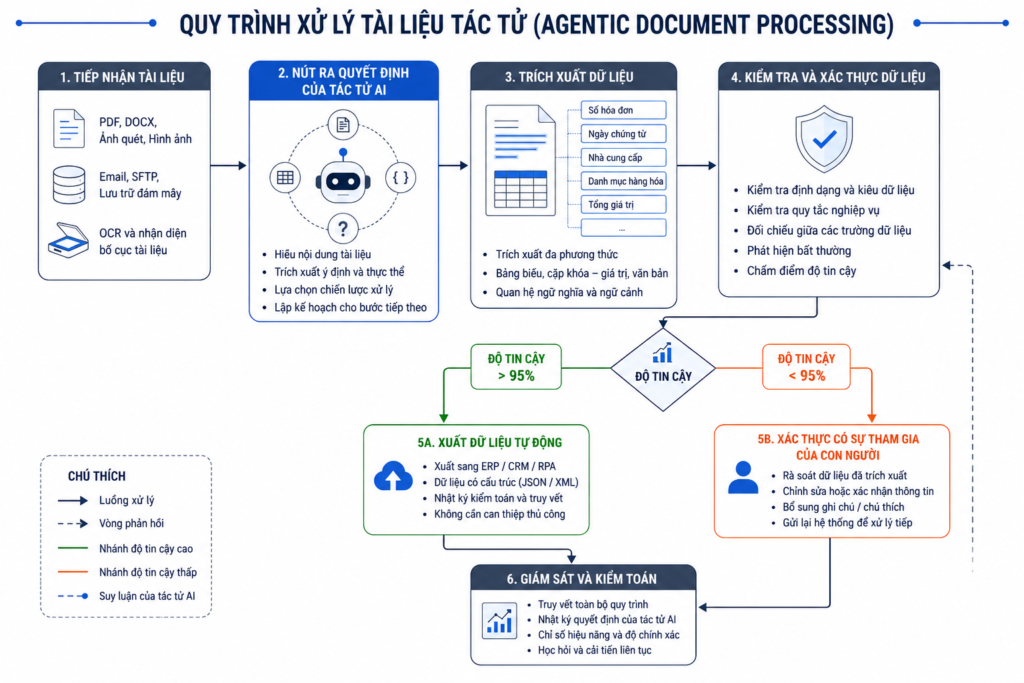
1. Phương thức xử lý tác tử (Agentic OCR) và hệ thống tự trị
Sự khác biệt cốt lõi giữa hệ thống OCR cũ và các nền tảng thiết kế chuyên biệt cho AI (AI-native) như LlamaParse nằm ở mô hình xử lý tài liệu tác tử (Agentic Document Processing). Thay vì chuyển đổi thụ động hình ảnh thành văn bản thô, hệ thống AI hoạt động như một tác tử có khả năng tư duy đa bước.
Quy trình xử lý tác tử này bao gồm các bước tự động hóa khép kín:
- Phân loại tài liệu: Nhận diện loại văn bản ngay khi tiếp nhận.
- Xác thực dữ liệu (Validation): Kiểm tra tính hợp lệ và logic của thông tin trích xuất.
- Định tuyến thông tin (Routing): Tự động chuyển dữ liệu đến các phòng ban hoặc hệ thống đích phù hợp.
Một yếu tố quan trọng trong kiến trúc này là cơ chế Kiểm duyệt phối hợp (Human-in-the-loop – HITL). Khi hệ thống phát hiện các trường dữ liệu có độ tin cậy thấp, nó sẽ tự động giữ lại và chuyển cho nhân sự chuyên trách kiểm tra, ngăn chặn thông tin sai lệch đi sâu vào cơ sở dữ liệu hạ nguồn.
Về mặt kỹ thuật, các giải pháp như LlamaParse xem tài liệu như các đối tượng đa phương thức có cấu trúc (structured, multimodal objects). Phương pháp này giúp bảo toàn định dạng của các biểu đồ, sơ đồ và bảng biểu phức tạp, tạo ra các đầu ra chuẩn hóa (AI-ready outputs). Đây chính là nền tảng quan trọng cho các hệ thống RAG (Retrieval-Augmented Generation), đảm bảo thông tin đầu vào cho các mô hình ngôn ngữ lớn luôn chính xác và giảm thiểu hiện tượng ảo giác thông tin.
2. Tiêu chuẩn độ chính xác và sự phân hóa phân khúc
Năm 2026, ngưỡng chính xác 95% được coi là tiêu chuẩn tối thiểu để một giải pháp OCR được đưa vào vận hành thực tế tại doanh nghiệp. Dưới ngưỡng này, chi phí nhân công và thời gian rà soát lỗi sẽ triệt tiêu hoàn toàn hiệu quả kinh tế của việc tự động hóa.
Tuy nhiên, thị trường đang có sự phân hóa sâu sắc dựa trên tính chất phức tạp của dữ liệu đầu vào:
- Mô hình AI đa năng (như GPT-4V): Thường chỉ đạt độ chính xác từ 60% đến 75% khi xử lý các tài liệu đặc thù như bản vẽ kỹ thuật hoặc sơ đồ hệ thống.
- Mô hình AI chuyên dụng (như Pathnovo): Có khả năng đạt độ chính xác lên tới 99,5% đối với các thông số an toàn trọng yếu như áp suất thiết kế hoặc nhiệt độ giới hạn trong các ngành công nghiệp nặng.
Đối với các lĩnh vực kỹ thuật hoặc y tế, sai số chỉ 0,5% cũng có thể dẫn đến những sự cố nghiêm trọng. Do đó, các cam kết chặt chẽ về Thỏa thuận mức độ dịch vụ (SLA) đang thúc đẩy doanh nghiệp chuyển dịch sang sử dụng các mô hình được tinh chỉnh sâu cho từng ngành dọc.
3. Xu hướng chuyên biệt hóa ngành dọc và xử lý chữ viết tay
Kỷ nguyên của các công cụ đa năng “một kích cỡ cho tất cả” đang dần thu hẹp. Các doanh nghiệp hiện ưu tiên tích hợp các công cụ chuyên biệt sâu vào từng quy trình làm việc cụ thể:
- Lĩnh vực Tài chính: Nền tảng Veryfi tập trung tối ưu hóa cho các loại hóa đơn, biên lai với tốc độ xử lý dưới 2 giây.
- Lĩnh vực Kỹ thuật (EPC): Công cụ Pathnovo được thiết kế để hiểu sâu sắc các tiêu chuẩn ký hiệu kỹ thuật như ISA 5.1, ASME và AIAG. Hệ thống không chỉ nhận diện các vòng tròn hay đường thẳng đơn thuần, mà hiểu được mối quan hệ logic giữa các thẻ thiết bị (tags), đường ống dẫn và các cụm máy.
- Lĩnh vực Pháp lý và Hành chính: ABBYY tập trung vào khả năng xử lý đa ngôn ngữ và vận hành ngoại tuyến cho các tài liệu pháp lý phức tạp.
Sự tích hợp logic ngành (domain logic) trực tiếp vào mô hình giúp các công cụ này đạt khả năng vận hành ngay lập tức (zero-configuration) mà không cần trải qua giai đoạn đào tạo lại (retraining) cho từng mẫu tài liệu mới.
Đối với bài toán chữ viết tay – vốn là điểm yếu của các công cụ mã nguồn mở truyền thống như Tesseract – các mô hình đa phương thức hiện đại như GPT-4o hay Claude 3.5 đã cải thiện đáng kể khả năng nhận diện. Tuy nhiên, trong khi các mô hình ngôn ngữ lớn (LLM) mạnh về việc đọc hiểu ngữ cảnh chung của một ghi chú, thì các công cụ chuyên sâu như ABBYY FineReader lại tối ưu hơn trong việc trích xuất cấu trúc dữ liệu từ các biểu mẫu viết tay phức tạp với độ chính xác đạt 94%. Dữ liệu sau đó được định dạng chuẩn để đồng bộ thẳng vào các hệ thống quản trị doanh nghiệp lớn như SAP hay IBM Maximo.
4. Nghịch lý chi phí và bài toán tối ưu hóa ROI thực tế
Thị trường công nghệ trích xuất dữ liệu hiện tại cung cấp nhiều phân khúc chi phí khác nhau, cho phép doanh nghiệp lựa chọn theo quy mô dữ liệu và ngân sách:
| Tên công cụ / giải pháp |
Mức chi phí tiêu chuẩn |
Đặc tính kỹ thuật và chiến lược |
| AWS Textract |
0,0015 USD / trang |
Chi phí thấp cho văn bản cơ bản; tích hợp sâu trong hệ sinh thái AWS. |
| Mistral OCR |
1 – 2 USD / 1.000 trang |
Tối ưu hóa cho các dự án số hóa kho lưu trữ tài liệu quy mô cực lớn. |
| Azure AI Vision |
1,50 USD / 1.000 trang |
Phù hợp cho các doanh nghiệp đang vận hành trên nền tảng Microsoft. |
| Veryfi |
Từ 500 USD / tháng |
Độ chính xác đạt 99,9% cho chứng từ tài chính; xử lý thời gian thực dưới 2 giây. |
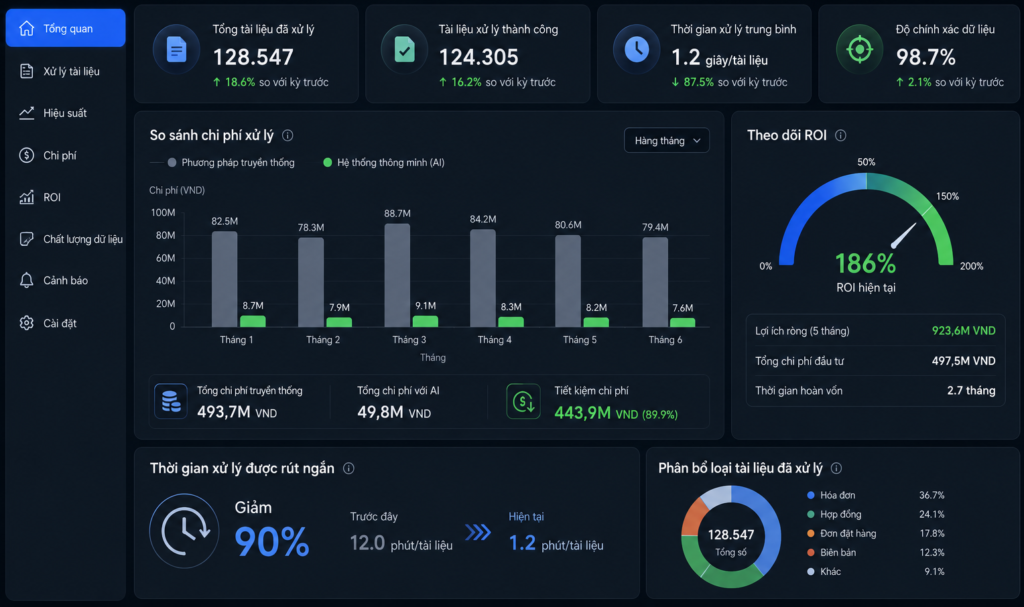
Để đánh giá hiệu quả đầu tư (ROI), hãy xem xét một bài toán kinh tế thực tế:
Nếu một doanh nghiệp xử lý trung bình 100 hóa đơn mỗi tháng bằng phương pháp thủ công:
- Thời gian nhập liệu trung bình: 5 phút / hóa đơn.
- Tổng thời gian tiêu tốn: 500 phút (tương đương 8,3 giờ làm việc).
- Chi phí nhân sự tính theo mức lương chuyên gia trung bình 50 USD / giờ: khoảng 415 USD / tháng.
Khi sử dụng một giải pháp chuyên biệt có chi phí thuê bao cố định khoảng 500 USD / tháng như Veryfi, mức chi phí trực tiếp có thể tương đương hoặc cao hơn một chút so với nhân công thủ công. Tuy nhiên, giá trị thực tế nằm ở việc loại bỏ hoàn toàn các rủi ro sai sót số liệu tài chính – những lỗi có thể gây thiệt hại hàng ngàn USD, đồng thời giải phóng thời gian của nhân sự cho các tác vụ chuyên môn có giá trị thặng dư cao hơn.
5. Yêu cầu bảo mật và các giải pháp xử lý cục bộ (Offline)
Mặc dù các giải pháp đám mây (Cloud AI) mang lại sự linh hoạt và tài nguyên tính toán lớn, việc đưa dữ liệu lên mạng vẫn là một rào cản pháp lý lớn đối với các ngành chịu sự kiểm soát nghiêm ngặt về bảo mật thông tin như Y tế (tuân thủ tiêu chuẩn HIPAA) hay Pháp lý (tuân thủ GDPR).
Trong bối cảnh đó, các giải pháp hoạt động hoàn toàn cục bộ (Local/Offline) đóng vai trò như những “pháo đài bảo mật”. ABBYY FineReader tiếp tục duy trì vị thế trong phân khúc này nhờ khả năng xử lý dữ liệu trực tiếp trên thiết bị của người dùng mà không cần kết nối internet. Với việc hỗ trợ tới 198 ngôn ngữ ở chế độ ngoại tuyến, giải pháp này đáp ứng yêu cầu của các tổ chức tài chính, luật sư và đơn vị y tế khi cần xử lý các tài liệu có độ mật cao nhưng vẫn yêu cầu độ chính xác tối đa.
Kết luận
Sự dịch chuyển từ “quét văn bản” sang “hiểu văn bản” đã định hình lại các quy trình vận hành dữ liệu trong doanh nghiệp. AI OCR không còn là một công cụ hỗ trợ chuyển đổi định dạng đơn thuần, mà đã trở thành một hệ thống tự trị có khả năng kích hoạt trực tiếp các luồng công việc không chạm (Zero-touch Workflows). Dữ liệu sau khi trích xuất không bị cô lập trong các tệp PDF tĩnh mà tự động liên thông với các hệ thống phân tích thời gian thực. Bài toán chiến lược hiện nay đối với các nhà quản lý không còn là tìm cách đọc tài liệu, mà là tối ưu hóa nguồn lực và thời gian tiết kiệm được để tập trung vào các hoạt động cốt lõi của doanh nghiệp.